Come creare una pipeline di Continuous Integration e Continuous Deployment (CI/CD) · DevOps
Creare una pipeline CI/CD su un progetto già avviato è un lavoro sfidante. In questa guida vi mostro come raggiungere al meglio questo obiettivo!


Introduzione
Una cosa che ho imparato in Pirelli è l’implementazione delle pipeline per avere la Continuous Integration (CI) e Continuous Deployment (CD), d’ora in poi lo chiamerò semplicemente CI/CD. Nascono sempre numerosi progetti con architettura a microservizi: il tempo al lavoro è sempre poco e i lavori ripetitivi mi annoiano facilmente… Cosa c’è di più ripetitivo di una messa in produzione di tutti questi microservizi? Queste pipeline automatiche quindi diventano essenziali per non passare la giornata a fare solo questo noioso mestiere.
Non voglio annoiarvi troppo parlando sui vari vantaggi che CI/CD comporta, se siete giunti su questo post significa che lo sapete già, quindi inizio subito con un esempio pratico.
Creazione della pipeline per GasLow Backend
Come esempio utilizzerò il backend di un mio progetto che ho creato nel mio tempo libero: GasLow. Sostanzialmente è un backend che è in grado di recuperare gli open data che riguardano i prezzi dei carburanti in Italia e di fornire queste informazioni in base alla propria posizione. L’app Android, basata su Flutter, che utilizza questo backend è disponibile gratuitamente sul Play Store.
La cosa importante per noi sono queste:
- Il backend è scritto in Node.js + TypeScript, il database è MongoDB.
- Il file di configurazione con i dati per connettersi al DB si trova nel file
.env, nella root del progetto. Ovviamente il file non è pubblicato su Git per evitare che il mondo intero sappia le credenziali del DB. Potete vedere un esempio di dati contenuti in questo file leggendo.env.example. - Il server di “produzione” si trova su Heroku su una macchina gratuita. In questa guida saremo in grado di automatizzare il deploy su Heroku.
- Sto implementando anche la versione AWS serverless, dove viene deployata usando CloudFormation. Purtroppo questa parte è un po’ troppo da spiegare in questa guida introduttiva sulla CI/CD. Magari farò una guida dedicata su questo argomento in futuro.
Prerequisiti
Per capire a pieno questa guida abbiamo bisogno di queste conoscenze:
- Un minimo di conoscenza di Git.
- Com’è strutturato un progetto in Node.js e i comandi base del suo package manager npm. Questa parte in realtà non è obbligatoria per capire la pipeline come concetto, serve solamente per capire la pipeline di questo esempio specifico.
Scegliamo il servizio di CI/CD
Il primo passo importante per automatizzare il tutto è scegliere il servizio che vogliamo utilizzare. La scelta è veramente ampia. Quelli che conosco ed ho utilizzato sono questi:
- CircleCI: molto potente e flessibile. È hostato da loro e quindi non abbiamo bisogno di una nostra macchina per farlo girare. Offre un piano gratuito di 1000 minuti/mese sia per i vostri progetti pubblici che privati, non è male per un uso hobbista. Per ora è la mia prima scelta per i miei progetti privati ed era quello che usavo in Pirelli fino ad un mese fa.
- GitLab: anche questo è potente quanto CircleCI. Si può utilizzare la versione hostata da loro come installarlo sulla vostra macchina. È un po’ diverso dagli altri perché offre un pacchetto completo per il vostro progetto (ha Git integrato quindi lo potete usare anche come repository). Per ora è la nostra prima scelta in Pirelli e stiamo infatti facendo una bella migrazione da CircleCI.
- Travis CI: forse è un pelino più indietro rispetto ai primi due. Per esempio non è possibile fare ancora un deploy di tipo manuale, a meno di non inventarsi hack come questo. Per manuale intendo avere un bottone che ci permetta di eseguire un deploy solo dopo una conferma. Questa funzione per me è molto utile per avere pieno controllo di quando vogliamo fare il deploy in produzione. A parte questo piccolo neo ha un grossissimo vantaggio: è gratis per tutti i progetti pubblici! Proprio per questo motivo lo uso per i miei progetti pubblici (come GasLow). La nostra guida si baserà su Travis CI.
- Jenkins: è una pietra miliare e il più antico di tutti. Io l’ho usato solo poche volte e sinceramente non mi ha mai entusiasmato più di tanto, soprattutto per quanto riguarda la UX. Ma questa è una mia opinione personale e quindi parecchio soggettiva.
Obiettivo della guida
In questa guida vorrei vivere con voi la creazione di una pipeline avendo un progetto già avviato e che è già in produzione. Perché farlo con un progetto già avviato? Perché è un caso d’uso tipico che si incontra al lavoro e probabilmente è la vostra situazione attuale, infine perché di “hello world” per la creazione della pipeline c’è già pieno il web. Ma solitamente sono esempi focalizzati sull’apprendimento del servizio che offre le pipeline, e non tanto per apprendere i concetti e le difficoltà che si incontrano nella vita reale.
Mettiamo in chiaro cosa vogliamo raggiungere: immaginiamo di essere al lavoro e come task della settimana ci è stato proposto di creare la pipeline CI/CD per il progetto GasLow. Alla fine della guida avremo una pipeline composta da due fasi:
- Esecuzione dei test: passo fondamentale per ottenere la Continuous Integration (CI).
- Deploy in produzione sulla macchina di Heroku: passo per ottenere il Continuous Deployment (CD).
Questo è il minimo indispensabile per ottenere una pipeline completa di CI/CD e per non allungare troppo la guida ci limiteremo a questi due passi. Una volta preso dimestichezza con l’argomento si può complicare la pipeline a piacere. Per esempio una tipica pipeline che utilizzo al lavoro è composta dai seguenti passi:
- Build e unit tests dell’applicazione.
- Creazione dell’immagine Docker attraverso il Dockerfile, push dell’immagine sul repository AWS ECR.
- Migrazione del database e deploy dell’immagine Docker in ambiente di DEV.
- Integration tests sull’ambiente di DEV.
- Migrazione del database e deploy con conferma manuale in ambiente di QLT utilizzato dal nostro QA Team.
- Migrazione del database e deploy con conferma manuale in ambiente di Produzione.
Registrazione a Travis CI
Questo passo è semplicissimo, vi basta andare sulla loro home page e premere sul bottone “SignUp”, inserite le vostre credenziali di GitHub, e a questo punto avete di fatto collegato Travis CI al vostro GitHub. Una volta fatto questo entrerete nella pagina principale di Travis CI.

sulla sinistra vi compariranno i vostri progetti GitHub che utilizzano Travis CI come servizio di CI/CD. All’inizio sarà vuoto ovviamente. Per ora non ci serve sapere altro.
Fork del progetto
Se volete provare con mano anche voi, potete fare il fork del mio progetto e buttare via il file .travis.yml perché lo ricreeremo insieme per formare la pipeline che abbiamo in mente.
Il commit di riferimento ha come hash d09f1068a14ddcdb857f1ced90b532680b050917, quindi per essere perfettamente allineati a questa guida dovremo fare il checkout di questo specifico commit, non escludo che il progetto possa avere profonde modifiche nel corso del tempo.
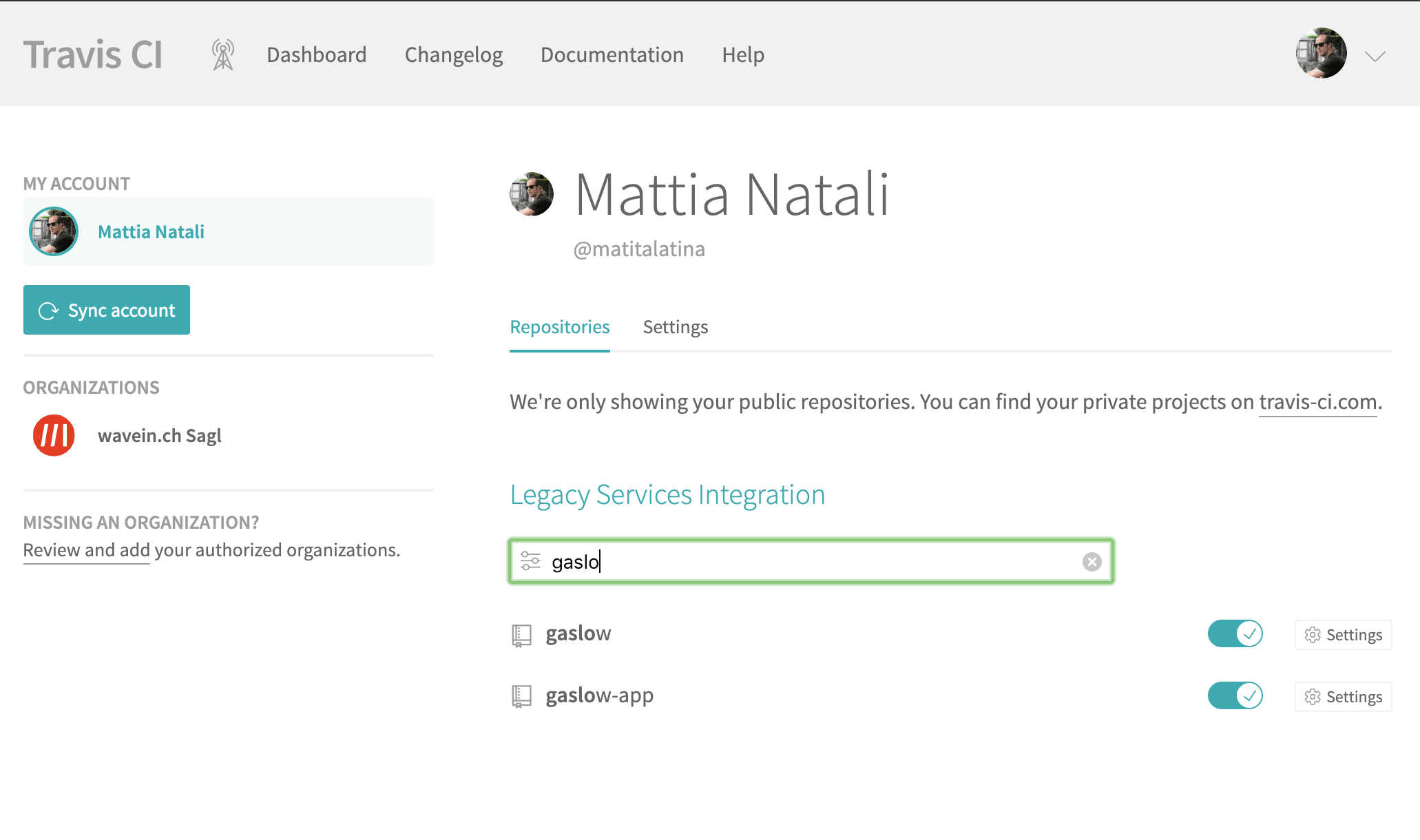
git checkout d09f1068a14ddcdb857f1ced90b532680b050917Una volta forkato e rimosso il file possiamo andare sui settaggi di Travis CI (menu utente in alto a destra -> Settings). In questa pagina dovrebbero comparire tutti i nostri repo, compreso questo appena forkato. Se non vedete nulla cliccate sul bottone Sync Account, per sincronizzare Travis CI. Poi possiamo vedere il repo gaslow come in figura, abilitiamo il toggle.
Ora abbiamo la repo forkata, Travis CI pronto e connesso ad esso. Ora inizia la parte divertente: mettiamo in piedi il primo step della nostra pipeline.
Implementazione della pipeline di Continuous Integration (fase di testing)
Testing in locale
Prima di andare a creare la pipeline poniamoci questa domanda: come si eseguono i test in locale? Il modo migliore per creare una pipeline automatica è di pensare tutti i vari step che dobbiamo fare in locale per raggiungere lo stesso obiettivo. Qui do per scontato che abbiamo un minimo di esperienza in Node.js e come funziona il package manager npm.
Uno che mastica Node.js da mattina a sera ha già pensato a come si fa: c’è il comando npm test… Ma siamo sicuri che basta solo questo? In questo caso stiamo dando per scontato un po’ di cose che per Travis CI non lo saranno affatto.
Per eseguire i test con npm test stiamo dando per scontato i seguenti punti:
- Sulla propria macchina c’è installato Node.js v8.
- Sulla propria macchina abbiamo MongoDB installato e attivo sulla porta standard
:27017. - Abbiamo installato tutte le dipendenze (tramite il comando
npm install) e che quindi abbiamo la cartellanode_modulescorrettamente popolata.
Quindi i passaggi corretti per eseguire i test su una macchina pulita sono i seguenti:
- Installa Node.js v8.
- Installa MongoDB e attivalo sulla porta di default
:27017. npm installper installare le dipendenze presenti nel filepackage.jsone quindi popolare la cartellanode_modules.npm testper eseguire i test.
Testing usando Travis CI
Ora che abbiamo capito i passaggi in locale, proviamo a tradurli in passaggi che possono essere digeriti da Travis CI.
Per far eseguire automaticamente i test a Travis CI abbiamo bisogno di un mezzo per comunicare. Il modo di comunicare con questo servizio è il file .travis.yml, proprio il file che vi ho fatto cancellare durante il fork del progetto. L’estensione del file magari vi può essere sconosciuta. yml viene usato per il formato YAML che sta per (YAML Ain’t Markup Language). È diventato lo standard de-facto nel mondo DevOps perché da un lato è “espressivamente” molto potente, dall’altro è molto semplice da leggere per un umano.
Questo formato, per quanto possa essere semplice da leggere, ha molte regole che ci vuole un po’ di tempo per padroneggiarle e conoscerle tutte. Comunque non dobbiamo preoccuparci più di tanto: noi useremo solo il minimo indispensabile e dei concetti molto di base. Io di solito utilizzo Learn yaml in Y minutes come cheatsheet per lo yaml: questo sito è molto conciso ed allo stesso tempo ricco di informazioni; dateci un’occhiata anche per altri linguaggi, non ve ne pentirete.
Iniziamo con il creare il file .travis.yml nella root di progetto. Al suo interno inseriamo questo contenuto:
language: node_js
node_js: '8'
services:
- mongodb
install: npm install
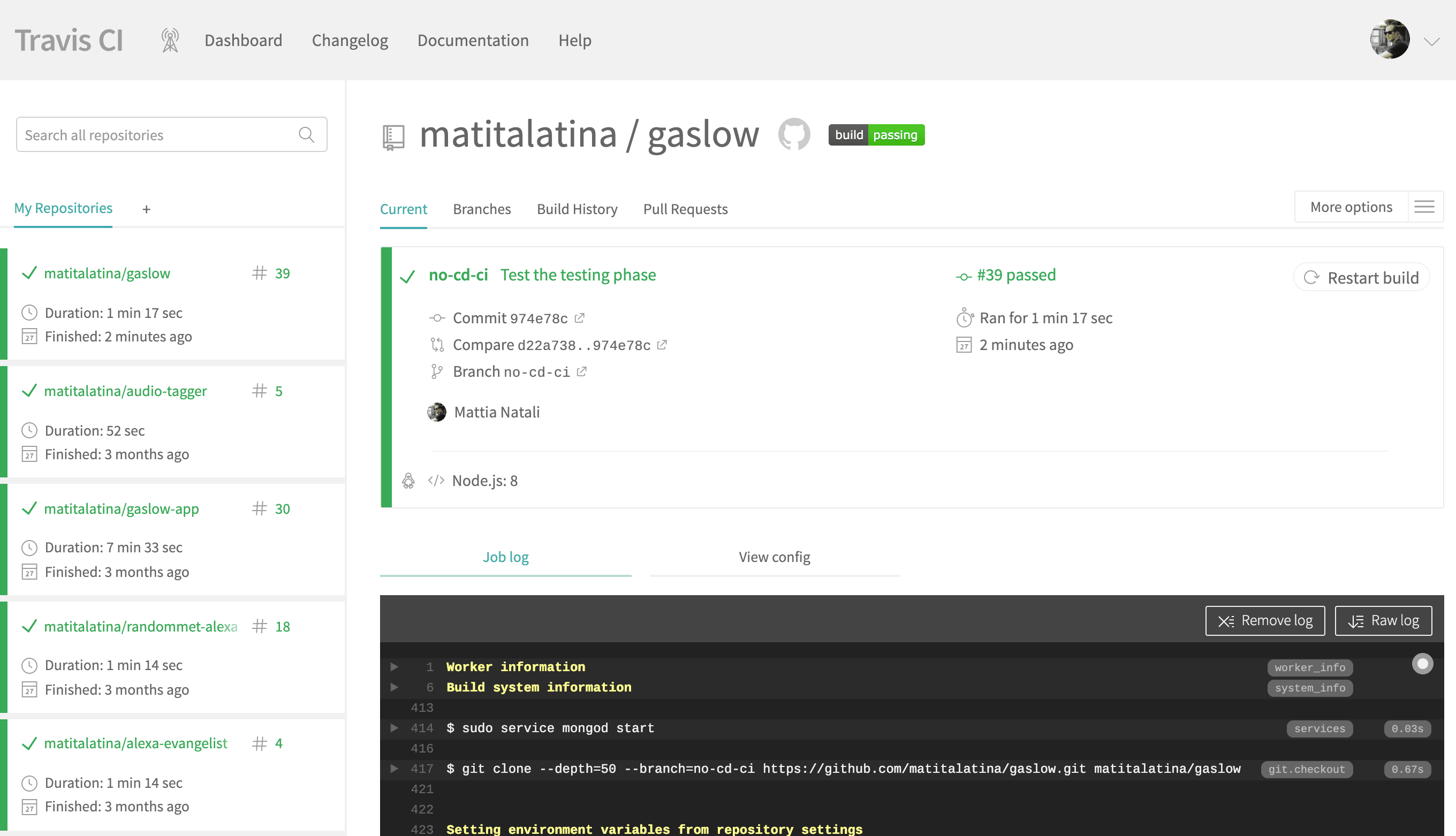
script: npm testIn questo modo, Travis CI è in grado di far girare i nostri test. Proviamo a committare il file, effettivamente vediamo che Travis CI ha iniziato a lavorare e che ha eseguito i test.
Ora proviamo a vedere le similitudini con i passaggi che avevamo bisogno in locale:
-
Abbiamo detto a Travis CI di installare Node.js v8? Sì attraverso la direttiva
language: node_js node_js: '8' -
Abbiamo detto a Travis CI di installare MongoDB e di aprire la porta standard di Mongo? Sì attravers la direttiva
services: - mongodb -
Abbiamo installato le dipendenze del progetto prima di eseguire i test? Sì attraverso l’esecuzione dello script
npm installdurante la fase di installazione del nostro job, attraverso la direttivainstall: npm install -
Abbiamo fatto girare i test? Sì attraverso l’esecuzione dello script
npm testdurante la fase principale del job, tramite la direttivascript: npm test
Quindi possiamo dire di aver eseguito gli stessi passaggi che facevamo in locale usando un linguaggio che Travis CI capisce. Non voglio dilungarmi troppo sul linguaggio che utilizza Travis CI perché è molto specifico al servizio che stiamo utilizzando: CircleCI, GitLab avrebbero usato un linguaggio leggermente diverso. Quello che deve passare qui è questo: Travis CI è come se fosse un foglio di carta bianco, siamo noi che dobbiamo istruirlo come eseguire i nostri test. Il modo migliore di istruirlo è di pensare prima ai passaggi che facciamo in locale, poi li rifacciamo nel linguaggio della piattaforma che noi utilizziamo.
Per chi volesse saperne di più sul linguaggio specifico di Travis CI, lascio qui dei link che approfondiscono gli argomenti appena trattati:
- Per conoscere i linguaggi supportati, nello specifico JavaScript.
- Per sapere come aggiungere dei nuovi servizi come MongoDB.
- Per conoscere le varie fasi di un job.
Deployment usando Travis CI
Ora che abbiamo eseguito i test vogliamo deployare il nostro codice su Heroku. Heroku, per chi non lo conoscesse, permette di deployare il proprio codice sulla loro piattaforma PaaS.
Prima di creare la pipeline, abbiamo bisogno di creare un’applicazione su Heroku, fortunatamente danno la possibilità di ospitare il nostro progetto gratuitamente.
Ci registriamo e creiamo una nuova app.
Ora torniamo sul file .travis.yml e aggiungiamo alla fine:
before_deploy:
- <STEP_MISTERIOSO>
- npm run build
deploy:
provider: heroku
api_key:
secure: '<API_KEY>'
app: <HEROKU_APP>
on:
branch: master
env:
- NODE_ENV=production
skip_cleanup: trueUna piccola spiegazione di quello che abbiamo aggiunto:
before_deployè la keyword per definire cosa bisogna fare appena prima della fase di deploy. La fase di deploy è il passo all’interno di un job che è adibito a deployare il nostro codice su Heroku. Il job, per Travis CI, si compone essenzialmente di tre fasi: install, script e deploy. Se volete approfondire, potete leggere direttamente dalla documentazione di Travis CI le varie fasi che compongono un job.<STEP_MISTERIOSO>è un passo essenziale per il deploy che non vi ho ancora detto, ne parlo più avanti.npm run buildè lo script che dobbiamo eseguire prima del deploy. Questo script è legato strettamente al nostro progetto. Se siete curiosi potete andare nel filepackage.jsone vedere che lo script build esegue il comandoparcel build src/server.ts --target node. Esso non fa altro che chiamare Parcel.js transpilare il codice TypeScript in JavaScript, fare il bundling, minificarlo e inserirlo nella cartella/dist. Alla fine di questo progetto abbiamo quindi il file/dist/server.jspronto per essere eseguito in produzione.deployè la keyword per definire cosa bisogna fare durante la fase di deploy.- Con
providerdefiniamo che stiamo usando Heroku come piattaforma. api_keyserve per definire le credenziali per poter effettivamente deployare con Heroku. Il prossimo passo sarà di sostituire'<API_KEY>'con le vere chiavi (criptate).app: <HEROKU_APP>indichiamo a Travis CI su quale app di Heroku vogliamo fare il deploy. Dobbiamo sostituire<HEROKU_APP>con il nome dell’applicazione Heroku che abbiamo creato nel passo precedente.- Con
on: branch: masterpossiamo fare il deploy solo quando pushiamo sul branchmaster. Senza questa direttiva ogni singolo push su un qualsiasi branch git farebbe scatenare il deploy automatico. - Con
env:possiamo definire le variabili d’ambiente che il nostro progetto avrà a disposizione su Heroku. Nel nostro caso abbiamo aggiunto la variabileNODE_ENV=productionche è uno standard nel mondo Node.js per definire che siamo su un ambiente di produzione. skip_cleanup: trueci permette di evitare la cancellazione dei file generati nel passo precedente. Durante la fase di test abbiamo eseguito il comandonpm installche popola la cartellanode_modulesche è essenziale per il corretto funzionamento del sistema. In questo modo possiamo evitare di rifarlo e quindi risparmiamo del tempo nella fase di deploy. Dobbiamo immaginare che la fase di deploy è separata dalla fase di script, quindi avremmo solo il codice sorgente senza questa direttiva.
Se vogliamo conoscere tutti i vari parametri che possiamo utilizzare per fare un deploy su Heroku possiamo leggere la documentazione ufficiale.
Ricapitolando ci sono ancora due cose da fare:
- Capire cosa dobbiamo fare nello
STEP_MISTERIOSO: ha a che fare con la configurazione del nostro progetto in produzione. Vi do un indizio: andate a leggere il file src/util/secrets.ts. - Recuperare l’
API_KEYdi Heroku criptata per far sì che Travis CI possa autenticarsi ed eseguire il deploy.
Capire lo step misterioso
C’è una parte che ho tenuto nascosto fin dall’inizio e che ora è giunto il momento di parlarne. Abbiamo detto che il progetto si basa su MongoDB, ma dove prende le credenziali per collegarsi? Abbiamo eseguito dei test precedentemente, eppure pare che si sia connesso senza problemi. Anche Travis CI, durante i test, si è connesso. Il recupero delle informazioni sulla connessione possiamo leggerlo nel file src/util/secrets.ts che riporto qui per semplicità:
import logger from "./logger";
import dotenv from "dotenv";
import fs from "fs";
if (fs.existsSync(".env")) {
logger.debug("Using .env file to supply config environment variables");
dotenv.config({ path: ".env" });
} else {
logger.debug("Using .env.example file to supply config environment variables");
dotenv.config({ path: ".env.example" }); // you can delete this after you create your own .env file!
}
export const ENVIRONMENT = process.env.NODE_ENV;
const prod = ENVIRONMENT === "production"; // Anything else is treated as 'dev'
export const SESSION_SECRET = process.env["SESSION_SECRET"];
export const MONGODB_URI = prod ? process.env["MONGODB_URI"] : process.env["MONGODB_URI_LOCAL"];
if (!SESSION_SECRET) {
logger.error("No client secret. Set SESSION_SECRET environment variable.");
process.exit(1);
}
if (!MONGODB_URI) {
logger.error("No mongo connection string. Set MONGODB_URI environment variable.");
process.exit(1);
}In pratica il codice si comporta in questo modo:
- Recupera il file
.env, se non c’è fai il fallback sul file.env.example. - Recupera il valore
SESSION_SECRETda questo file. - Recupera il valore
MONGODB_URIse sei in produzione, altrimentiMONGODB_URI_LOCAL.
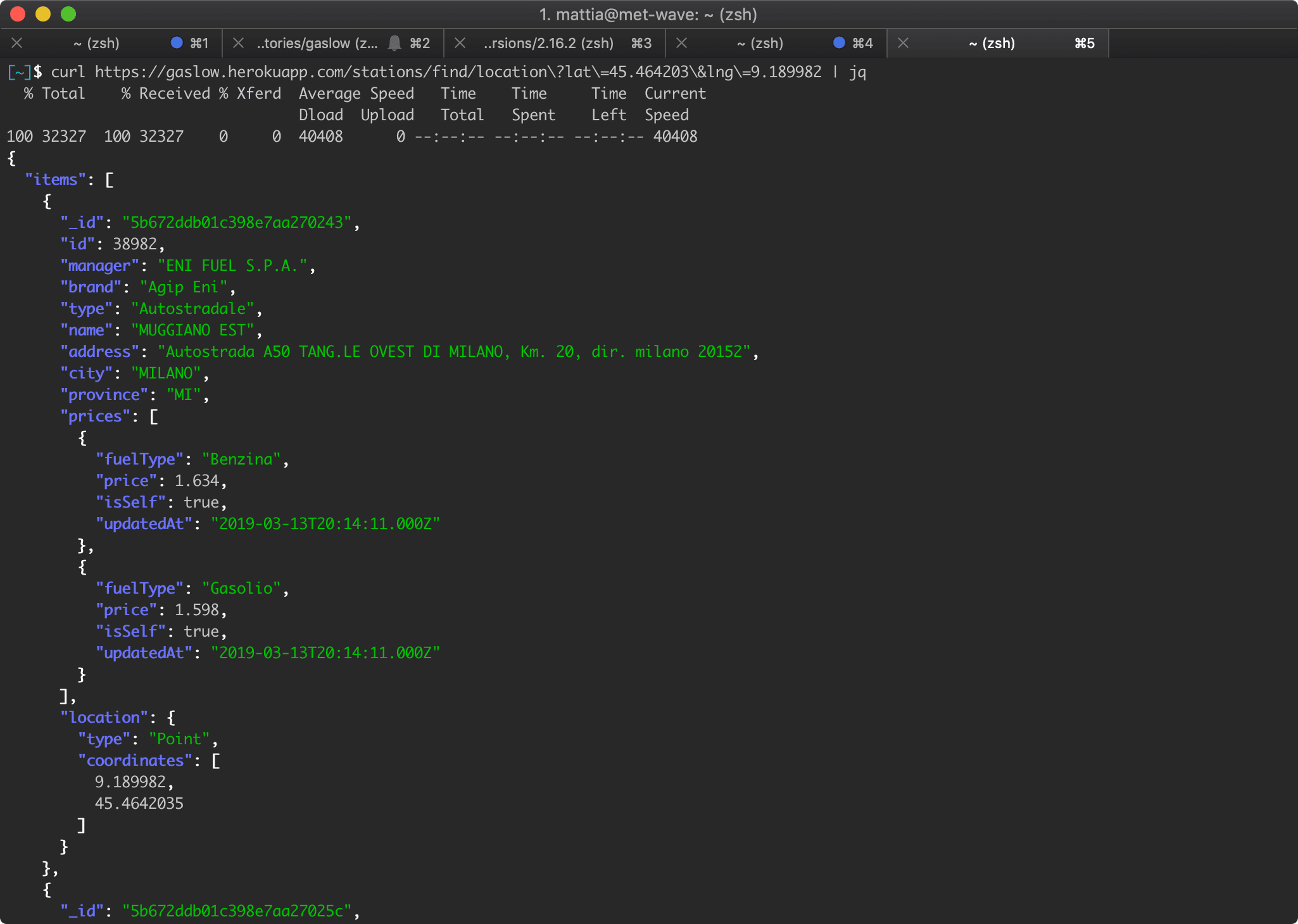
Finalmente possiamo capire come facevano i test a collegarsi a MongoDB senza che noi facessimo nulla: in pratica faceva il fallback sul file .env.example che è versionato su Git, andava a leggete il valore MONGODB_URI_LOCAL=mongodb://localhost:27017 e quindi si collegava al nostro MongoDB locale, mentre Travis CI si collegava al servizio MongoDB che abbiamo instanziato nella pipeline.
Il nostro compito è quello di trovare un modo per caricare il file .env in produzione in modo sicuro, versionato, ma allo stesso tempo che non abbia scritto in chiaro tutte le credenziali per accedere al nostro MongoDB.
Caricare in modo sicuro il file .env
Una soluzione al problema precedente ci è data direttamente da Travis CI. Per questo step abbiamo bisogno di Travis CI Command Line Client che su Mac possiamo installare in questo modo:
sudo gem install travis
travis loginGrazie ad esso possiamo criptare i file in modo sicuro e salvare nella repo il file criptato senza aver paura che qualcuno possa rubarci le credenziali.
Il primo passo è quello di creare il file di configurazione .env pronto per la produzione, dobbiamo stare attenti a non caricarlo per nessun motivo su Git, non è criptato e se lo versioniamo chiunque è in grado di accedere al nostro DB! Se state lavorando sul mio progetto ci ho già pensato io. Se andiamo infatti nel file .gitignore notiamo che il file .env è nella blacklist dei file da non tenere in considerazione con Git.
Allora creiamo il file .env con gli stessi dati che trovate nel file .env.example
# Get this from https://mlab.com/home after you've logged in and created a database
MONGODB_URI=mongodb://<mlab_user>:<mlab_password>@<mlab_connection_url>
# This is standard running mongodb locally
MONGODB_URI_LOCAL=mongodb://localhost:27017
SESSION_SECRET=<session_secret>Dobbiamo modificare due parti:
- In
MONGODB_URI, sostituiamo<mlab_user>,<mlab_password>,<mlab_connection_url>con le nostre credenziali del DB che vogliamo usare in produzione. Io utilizzo il servizio mLab. - Sostituiamo
<session_secret>con una stringa alfanumerica casuale.
Ora cancelliamo il file .env.enc, dove ci sono le mie chiavi criptate, perché ora andremo a creare il nostro file criptato. Con i valori che abbiamo appena inserito nel file .env. Per questo passo usiamo le linea di comando di Travis CI.
travis encrypt-file .envIl terminale vi dirà di inserire nel file .travis.yml una stringa del genere
openssl aes-256-cbc -K $encrypted_0a6446eb3ae3_key -iv $encrypted_0a6446eb3ae3_iv -in .env.enc -out .env -dquesto è esattamente quello che dobbiamo scrivere nello step misterioso!
Andiamo allora ad aggiornare il file .travis.yml, la fase before_deploy sarà così
before_deploy:
- openssl aes-256-cbc -K $encrypted_0a6446eb3ae3_key -iv $encrypted_0a6446eb3ae3_iv -in .env.enc -out .env -d
- npm run buildIl comando che abbiamo appena aggiunto non fa altro che decodificare il file criptato prima di fare il deploy.
Ottenere l’API key criptata di Heroku
Siamo quasi alla fine, ora ci manca solo di inserire nella nostra pipeline l’API key criptata per permettere a Travis CI di poter fare il deploy tramite Heroku.
Per questo passo abbiamo bisogno di Heroku CLI installato sul nostro PC. Se avete Mac vi basta scrivere nel terminale (se avete installato brew)
brew tap heroku/brew && brew install herokuCi autentichiamo con Heroku usando il comando
heroku logined infine scriviamo questo comando per ottenere l’API Key
travis encrypt $(heroku auth:token)Il comando ci ritornerà l’API Key, dobbiamo inserirla al posto di '<API_KEY>' nel file .travis.yml.
Fatto questo avremo quindi concluso il lavoro e possiamo goderci la nostra pipeline di Continuous Integration e Continuous Deployment!
Consigli sulla creazione delle pipeline
Ora che abbiamo visto un caso d’uso reale voglio condividere con voi qualche consiglio. Spero che vi faranno evitare un po’ di mal di testa che invece mi sono beccato:
Prima la creiamo più è semplice
L’implementazione della CI/CD prima la si crea, più si risparmia tempo, ma soprattutto più è semplice! Idealmente è meglio farla durante la creazione del progetto. Le motivazioni sono tante:
- Durante la creazione del progetto stiamo già lavorando sulla questione configurazione e dipendenze del progetto. Quindi tutto quello che stiamo facendo localmente per impostare il nostro ambiente locale, ci basta fare il corrispettivo nella pipeline. Inoltre se sappiamo che stiamo implementando una pipeline fin dall’inizio, evitiamo di creare dei test o delle configurazioni che sono troppo legate alla nostra macchina locale, evitiamo di scrivere configurazioni strane che ci complicano la pipeline proprio perché ci è difficile replicarlo in Travis CI (come per esempio il recupero di file che si trovano in cartelle al di fuori del nostro progetto Git).
- Non dobbiamo fare Reverse Engineering sul progetto per capire come configurarlo: nessuno ci avvertirà di trovare “lo step misterioso” nella vita reale e nessuno ci dirà di guardare il file src/util/secrets.ts per avere qualche indizio. In questa guida l’ho fatto per evitare di perdere troppo tempo. Senza questo aiuto avremmo dovuto sbattere la testa numerose volte e fare un minimo di Reverse Engineering del progetto per capire effettivamente come funzionava il recupero delle credenziali. Tutto questo poteva essere evitato se chi ha ideato questo recupero delle credenziali, avesse mantenuto aggiornata la pipeline. E chi è nuovo sul progetto, gli basta vedere il file
.travis.ymlper capire esattamente il procedimento per ottenere una versione locale funzionante. - Si evita l’errore umano nei deploy: averlo automatizzato è un vantaggio perché non si hanno errori grossolani nel deploy. Immaginate che voi dobbiate eseguire numerosi deploy al giorno… Dopo un po’ abbasserete la guardia e la concentrazione, l’errore per disattenzione è dietro l’angolo e fare errori nel deploy può costare molto caro!
- Si risparmia tempo: banalmente prima creiamo una pipeline più ore uomo risparmiamo. Nessuno in azienda è responsabile del deploy, chiunque può farlo. Sono stato in aziende dove il deploy era manuale, e ho visto una persona che era occupata tempo pieno solo per i deploy nei momenti più frenetici. Secondo me è inaccettabile. Gli strumenti per automatizzare ci sono e sono alla portata di tutti. Usiamoli!
Pensiamo ad impostare la pipeline in locale
Provare direttamente su Travis CI può portare via molto tempo. Per esempio se abbiamo problemi nel deploy, dobbiamo pushare le nuove modifiche, attendere tutti i passi precedenti e poi magari ritrovarsi un bell’errore dopo 15 minuti. In questo caso tentiamo di fixare il problema caricando le nuove modifiche e il ciclo ricomincia… Tutto questo porta via ore. Il modo migliore per evitare tutto questo è provare localmente i passaggi. Un po’ come abbiamo fatto in questa guida durante la creazione della pipeline di Continuous Integration. Per raggiungere questo obiettivo dobbiamo creare degli step che siano agnostici rispetto al servizio di CI/CD che utilizziamo. Solitamente io creo una cartella con tutti gli script utili per il deploy. In questo modo posso invocare questi script anche in locale e testare più velocemente la corretta esecuzione. Inoltre se teniamo in mente questo punto sarà più facile anche raggiungere il prossimo.
Non focalizziamoci troppo sul singolo servizio di CI/CD
In questa guida abbiamo usato Travis CI, nel lavoro precedentemente usavamo Jenkins. Nel lavoro attuale usavamo CircleCI, ora invece usiamo GitLab CI. Insomma vi capiterà di usare di tutto che però tutti risolvono lo stesso problema: automatizzare l’integrazione ed il deploy. Cerchiamo quindi di focalizzarci sui concetti di base e non tanto su come farlo su uno specifico servizio. Quest’ultima parte è semplice se abbiamo chiaro cosa dobbiamo raggiungere: basta leggere la guida del servizio specifico. Questo modo di lavorare ci dà parecchia flessibilità sia al lavoro che nei nostri progetti hobbisti. Infine questa flessibilità ci rende liberi di usare un servizio in base ai vantaggi che esso porta: in questa guida abbiamo usato appunto Travis CI perché è gratuito per i progetti open source, ma non è di certo il migliore sulla piazza. Questo non sarebbe possibile se usassimo solo ed esclusivamente un servizio.
Leggiamo delle pipeline già fatte
Dobbiamo ricordarci che non siamo gli unici sulla faccia della terra che stanno pensando di creare una pipeline. Non sottovalutiamo quindi la possibilità di vedere le pipeline dei progetti open source! Ci sono numerosi progetti su GitHub che mostrano degli esempi pratici di pipeline che molto probabilmente risolvono tutto o in parte i nostri problemi. Così facendo possiamo vedere anche dei modi diversi di ragionare che è sempre utile per migliorare il proprio bagaglio culturale. Ricordo infine che Travis CI è gratis per i progetti open source, è il motivo principale per cui ho deciso di scrivere questa guida. Quindi GitHub è pieno di pipeline fatte con Travis CI!
Non cerchiamo la perfezione
Ricordiamoci che il nostro lavoro non è di passare giorni a fare pipeline. È sempre possibile ottimizzarla per velocizzarla, ma come tutte le ottimizzazioni richiedono tempo. Il mio consiglio è di raggiungere il minimo indispensabile per raggiungere l’obiettivo, anche se magari non è la soluzione più elegante possibile. Poi ricordiamoci che col tempo impariamo nuovi concetti, come per esempio il caching e la possibilità di eseguire più job in parallelo, conosciamo meglio il sistema e quindi sarà più semplice per noi ottimizzarla impiegandoci meno tempo. Quindi teniamo sempre a mente che la pipeline è uno strumento che velocizza e automatizza il nostro lavoro… Ma se impiega 5 minuti o 10 minuti cambia davvero poco lato nostro, quindi non spendiamo ore o giorni per queste ottimizzazioni, soprattutto nei primi stadi dove le sfide sono già tante.
Conclusioni
Spero che con questa guida abbiate toccato con mano cosa significhi implementare una pipeline di Continuous Integration e Continuous Delivery su un progetto già esistente. Le difficoltà, come abbiamo visto, sono maggiori se il progetto è già avviato. Quindi, la prossima volta che inizierete a costruire una vostra idea, ricordatevi di pensare subito alla pipeline CI/CD; non ve ne pentirete. In questo modo potrete delegare questi task ad una macchina e voi potrete concentrarvi esclusivamente a ciò che porta realmente valore al vostro progetto: lo sviluppo del codice.
Alla prossima!
Hai imparato qualcosa di nuovo?
Aiutami a creare altri contenuti come questo!
Rimanere aggiornati è fondamentale
Ricevi le ultime novità via email